




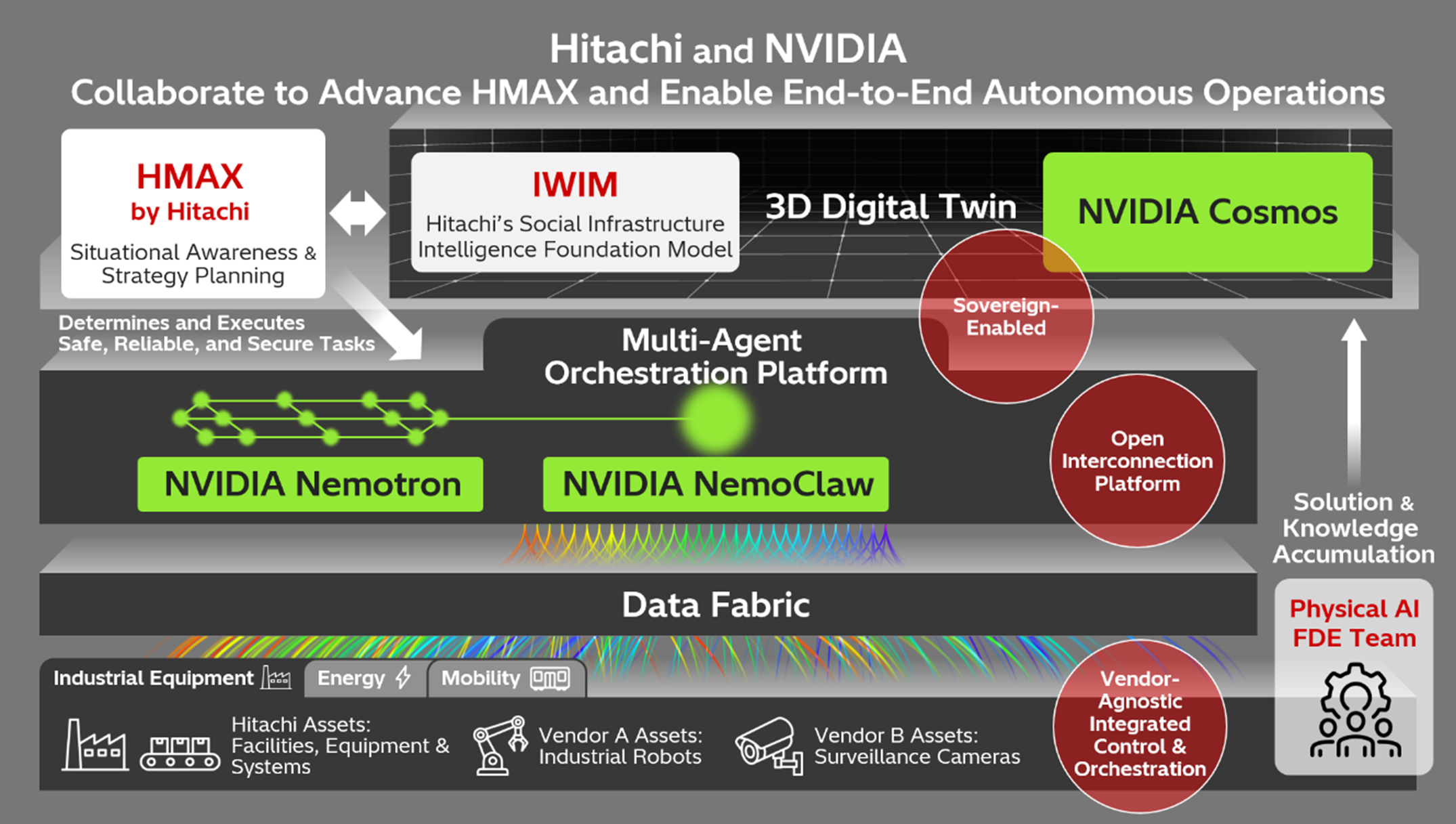






















NEC Develops High-speed Generative AI Large Language Models (LLM) with World-class Performance
NEC Corporation has expanded its
"NEC cotomi" generative AI services with the development of "NEC
cotomi Pro" and "NEC cotomi Light," two new high-speed
generative AI Large Language Models (LLM) featuring updated training data and
architectures.
With the rapid development of generative AI in
recent years, a wide range of organizations have been considering and verifying
business transformation using LLMs. As specific application scenarios emerge,
there is a need to provide models and formats that meet customer needs in terms
of response time, business data coordination, information protection and other
security aspects during implementation and operation.
NEC’s newly developed NEC cotomi Pro and NEC
cotomi Light are high-speed, high-performance models that deliver the same high
performance as global LLMs, but at more than ten times the speed.
Generally, to improve the performance of an LLM, a
model needs to be made larger, but this slows down the operating speed.
However, NEC has succeeded in improving both speed and performance with the
development of an advanced new training method and architecture.
"NEC cotomi Pro" achieves performance
comparable to top-level global models such as "GPT-4" and
"Claude 2," with a response time that is approximately 87% faster
than GPT-4 using an infrastructure of two graphics processing units (GPU). In
addition, the even faster "NEC cotomi Light" has the same level of
performance as global models such as "GPT-3.5-Turbo," but can process
a large number of requests at high speed with an infrastructure of about 1 to 2
GPU, providing sufficient performance for many tasks.
Specifically, in an in-house document retrieval
system using a technique called RAG, the system achieved a correct response
rate higher than GPT-3.5 without fine-tuning and a correct response rate higher
than GPT-4 after fine-tuning, with a response time that is approximately 93%
faster.
Leave A Comment