


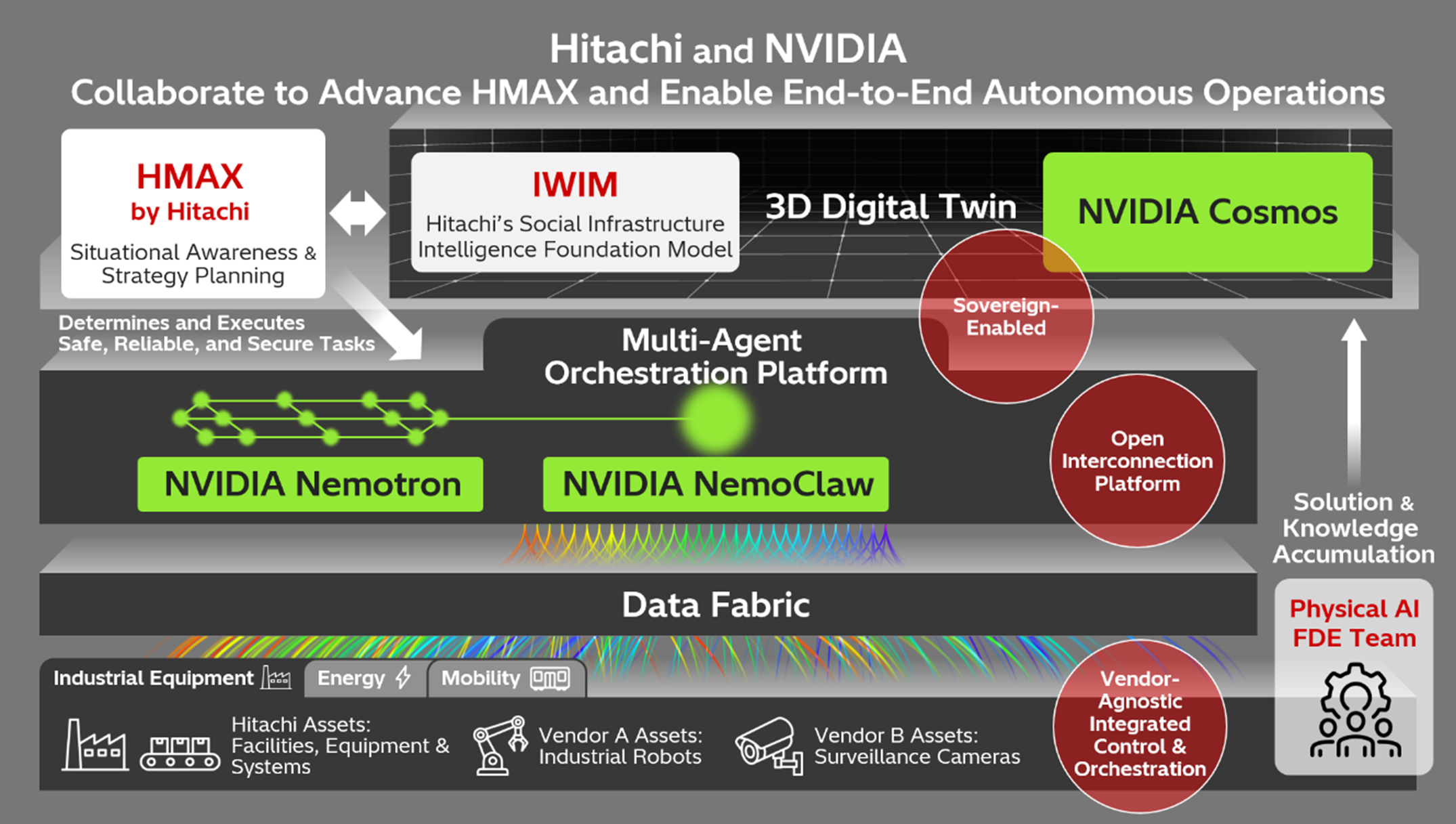






















Gartner Highlights 9 Principles to Improve Cloud Resilience
Infrastructure &operations (I&O) leaders must deploy
9 principles to maximize the resilience of cloud environments, according to
Gartner, Inc.
“The cloud is not magically resilient and software
bugs, not physical failures, cause almost all cloud outages,†said Chris
Saunderson, Sr Director Analyst at Gartner. “In the cloud, outages almost never
involve the entire cloud provider, nor are service outages likely to be total.
Instead, partial failures, degradations of service, individual service problems
or local problems are typical.â€
The I&O team
needs to understand the characteristics and common causes of cloud outages.
They include that most failures are partial, they tend to be intermittent or involve
performance degradation where they are less immediately noticeable, and
resilience differences exist between the services cloud providers offer.
“Resilience is not a binary state,†said Saunderson “No one
can claim absolute resilience — not you, and not any cloud provider. Clouds
should be as or even more resilient than on-premises infrastructure, but only
if the I&O team uses them in a resilient manner.â€
1-Business Alignment: Align resilience requirements to
business needs. Without this alignment on requirements, teams will fall short
of resilience expectations or will overspend.
2- Risk-Based Approach: Take a risk-based approach to
resiliency planning that extends beyond catastrophic events. Put more emphasis
on the more common failures that organizations have greater control to
mitigate.
3- Dependency Mapping: Build dependency graphs that map all
middleware components, databases, cloud services and integration points so they
can be architected and configured for resilience and included in both
reliability and disaster recovery (DR) planning.
4- Continuous Availability: The continuous-availability
approach focuses on keeping applications, services and data available at all
times and service levels with no downtime and limited impact during a failure
event.
5- Resilient-By-Design: The application itself should be
resilient by design. Infrastructure resilience alone is insufficient to deliver
the zero-downtime services that end users expect.
6- DR Automation: Implementing fully (or near fully)
automated disaster recovery (DR) — either through the organization’s own tools
or through third-party cloud-native DR tools — provides the foundation needed
to meet aggressive recovery time objectives (RTOs) and allows DR to be routinely
tested.
7- Resilience Standards: Adopt resilience standards beyond
architecture and DR. Resilient systems require teams to focus on quality,
automation and continuous improvement, and infuse quality throughout the life
cycle of an application.
8- Favour Cloud-Native Solutions: Cloud providers have a
significant range of solutions that can be used to improve resilience.
Where viable, I&O leaders should take advantage of these solutions rather
than trying to invent their own alternatives and adding even more
complexity.
9- Business Functions Focus: Rather than restricting
thinking to only “failing over†like-for-like, explore alternatives, such as
lightweight IT alternatives or lightweight application substitutions that provide
the bare minimum business-critical functionality required.
Leave A Comment